Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation
 tune_a_video
tune_a_videoAbstract
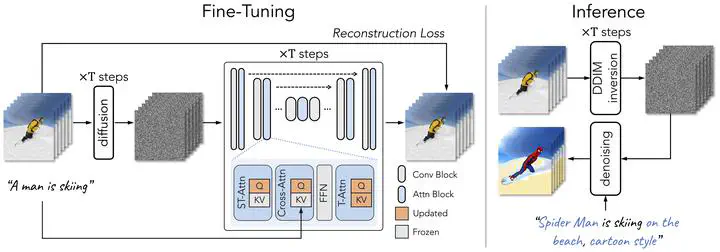
To replicate the success of text-to-image (T2I) generation, recent works employ large-scale video datasets to train a text-to-video (T2V) generator. Despite their promising results, such paradigm is computationally expensive. In this work, we propose a new T2V generation setting—One-Shot Video Tuning, where only one text-video pair is presented. Our model is built on state-of-the-art T2I diffusion models pre-trained on massive image data. We make two key observations (1) T2I models can generate still images that represent verb terms; (2) extending T2I models to generate multiple images concurrently exhibits surprisingly good content consistency. To further learn continuous motion, we introduce Tune-A-Video, which involves a tailored spatio-temporal attention mechanism and an efficient one-shot tuning strategy. At inference, we employ DDIM inversion to provide structure guidance for sampling. Extensive qualitative and numerical experiments demonstrate the remarkable ability of our method across various applications.
Add the publication’s full text or supplementary notes here. You can use rich formatting such as including code, math, and images.